Resiliency Strategies for AWS
Introduction
The day is October 20, 2025, and the most recent major AWS outage is fresh in my mind. Around 3 am EDT, AWS began investigating the incident affecting the us-east-1 region. This story is one that’s played out many times before–a widespread outage in one region or another affecting multiple companies’ primary hosting region. AWS’s event summary highlighted some issues with services in other regions having issues, but the outage was largely contained to us-east-1. A similar incident in December 2021 caused a major service outage for a vendor that my then-employer used for multi-factor authentication. These incidents highlight the same issue at different times: reliance on a single region for primary operations with inadequate or no recovery plans. According to Gartner, AWS’s work to reduce global reliance on us-east-1 over the last four years helped to confine this outage.
In this article, I will discuss foundational resiliency planning, strategies for dealing with outages, and services that AWS has put in place to help customers handle service outages. By the end, you’ll have tools in hand to plan for outages like the above and reduce time-to-recovery when they inevitably happen.
In Defense of AWS
First, I want to start by defending AWS. The knee-jerk reaction for most people is to blame the Cloud Service Provider (CSP) for causing the outage in the first place, but how many of us have seen outages in our own environments and been blamed? I recall a network switch fault at a former employer years ago when I was a Network Security Engineer that resulted in the Networking team bearing blame for an after-hours service outage for a large portion of our user base, despite the network team being quick to jump into their cars and drive for an hour to the site to resolve the issue. In reality, no one was to blame for that outage. The network team quickly restored the site to normal operation, identified the root cause (thanks to a robust network management and logging infrastructure), and resolved the root issue in that week’s maintenance window.
AWS regional outages are no different. They can be caused by power outages, natural disasters, and, yes, misconfigurations. Even though they’re the largest CSP in the world, they are not immune to environmental damage and bad luck. What AWS has done, however, is provide multiple regions for customers to deploy into and many service options that range across different compliance and cost requirements to help customers manage their own resiliency within AWS. They have also built resilient infrastructure so that a single regional outage rarely affects services outside of the region. A regional outage, in effect, should never fully affect a hosted application unless recovery and contingency planning at the customer were inadequate or non-existent.
Planning for Recovery
Resiliency, Redundancy, and High Availability
Before we can discuss planning, we need to define a few concepts within the context of AWS.
- Resiliency: AWS defines resiliency as “the ability of a workload to recover from infrastructure or service disruptions, dynamically acquire computing resources to meet demand, and mitigate disruptions, such as misconfigurations or transient network issues.”
- High Availability: Availability refers to the ability to access data or an application when required. High availability refers to the practice of reducing the MTTD and MTTR (mean time to detect and mean time to recovery, respectively) and increasing the MTBF (mean time between failures) by various means, including redundancy. High Availability is NOT disaster recovery.
- Redundancy: Redundancy is having spare capacity in excess of requirements in an effort to mitigate service disruptions. For example, a redundant deployment for EC2 might look like Need: 1 instance; Deployed: Auto-Scaling Group with a minimum of 2 instances. Read more at AWS.
- Recovery Time Objective (RTO): RTO is the maximum acceptable delay from service interruption to service restoration. This is defined by the customer and should be a risk-based calculation that includes input from stakeholders. Effectively, how long can the service be down?
- Recovery Point Objective (RPO): RPO is the maximum acceptable amount of time since the last data recovery point. This is defined by the customer and should be a risk-based calculation that includes input from stakeholders. Effectively, how often should we take snapshots/backups?
Planning for Disaster
The customer must conduct recovery planning–this may include Business Continuity, Incident Response, and Disaster Recovery Planning–because AWS cannot determine your RTO and RPO targets for you (recall the Shared Responsibility Model). To that end, the customer must perform Business Continuity and Disaster Recovery Planning in a way that meets your RTO/RPO requirements.
Recovery Strategies
Minor localized service disruptions occur all the time and require highly available design, but disasters will typically remove an entire region from service. In these cases, you must select a strategy that works best for your RTO/RPO targets, organization cloud spend strategy, and risk appetite. A healthy environment will also use various of these strategies for different workloads to best optimize cost and resiliency based on workload and data criticality. AWS lists a four main strategies:
- Backup & Restore
- RTO/RPO: Hours
- Pilot Light
- RTO/RPO: 10s of minutes
- Warm Standby
- RTO/RPO: Minutes
- Multi-Site Active/Active
- RTO/RPO: Real-time
Backup & Restore
This strategy is the lowest-cost solution and presents the longest time to recovery (TTR), with the expected duration being hours. This strategy consists of data backups to another region and will require provisioning of resources after the disaster event. Once the customer has provisioned the resources, they will restore the data from the backups, which will account for the bulk of the TTR.
This is typically the best strategy for low-priority workloads/data or those not necessarily critical to business functions. Often, disruptions of these workloads will fall within the RTO, so the customer may not have to execute the recovery plan in this case; however, the best option for resources is to use an Infrastructure-as-Code (IaC) approach, such as Terraform, CloudFormation, or AWS SDK, so that infrastructure can be quickly provisioned once required.
Pilot Light
This strategy adds some cost and complexity over Backup & Restore, but it decreases TTR to 10s of minutes. This strategy provides a well-balanced approach that replicates data in accessible storage (such as S3 Standard instead of Glacier). Additionally, the customer will pre-provision some AWS resources and scale them to requirements after an event, meaning there will be idle services in the recovery region.
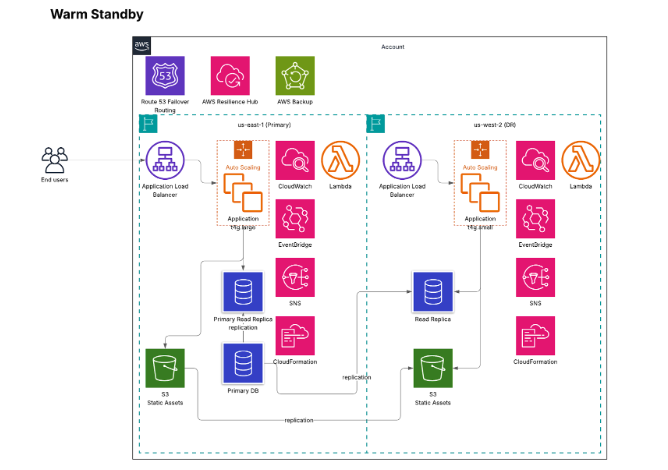
Warm Standby
This strategy increases cost and complexity further beyond Pilot Light. It builds upon what Pilot Light deploys in that the data in the recovery region is live; however, in Warm Standby, a scaled-down version of the production services is deployed and running. This should be used for business-critical services that can withstand minutes of downtime, but not the 10s of minutes TTR that Pilot Light allows. As with Pilot Light, the customer will scale services to meet production requirements after the disaster/disruption event.
Multi-Site Active/Active
This strategy represents the heaviest cost and complexity for setup, but the shortest TTR for those mission-critical services that require near-real-time recovery and near-zero data loss. This option serves as always-on redundancy, which allows for cross-region load balancing in normal operations and near-instantaneous recovery during a disaster/disruption event.
Selecting the Right Strategy
For any customer, selecting the right recovery strategy will require careful planning and many conversations with stakeholders, including data owners, data custodians, application and product owners, senior leadership, and engineering teams. It will represent a balance of business and uptime requirements, and it will require an inventory of the infrastructure to properly determine which strategy is right for a given workload.
Example Warm Standby Recovery Architecture
AWS Services for Resilience
AWS Resilience Hub
AWS Resilience Hub is a central location to manage resiliency and recovery in AWS. It integrates with many services, allowing customers to assess applications, take actions, assess application resilience, and track resilience posture. As you’re planning and deploying your recovery strategies, Resilience Hub will help you orchestrate activities and verify that the resources you’ve deployed meet your defined requirements.
AWS Backup
AWS Backup provides a fully-managed centralized backup service to define, manage, and restore data backups and snapshots across your entire organization.
AWS Elastic Disaster Recovery (DRS)
AWS Elastic Disaster Recovery is an agent-based service that helps you minimize downtime for your on-premises and cloud-based applications. DRS orchestrates the process, provisioning required replication servers in AWS (launched and terminated automatically as needed), and the agent replicates data to EBS volumes from your source servers, and creates recovery instances in your designated recovery subnet.